
In this article I showed how to extract keywords from a text file to create an index, and I reassembled the text again from the compressed file. In this article, I render the compressed file with a limited character set. Here is the code:
%found = ();
%index= ();
$i=1;
# this will grab 196 words with more than 1 letter,
# repeated more than 8 times
open (SQ, "< snowqueen");
open (SQI, "> snowqueeni");
while (<SQ>){
while ( /(\w['\w-]*)/g ){
if (!(exists $found{uc $1})){
$found{lc $1}++;
if (($found{lc $1}>8) && (length(lc $1)>1)){
$found{uc $1}=$i;
print SQI (uc $1)."\n";
$i++;
}
}
}
}
close (SQ);
close (SQI);
open (SQC, "> snowqueenc");
open (SQ, "< snowqueen");
$nonindex=0;
while (<SQ>){
if (/^$/ ) {
s/^/ endofparagraph /g;
}
s/\./ endofsentence /g;
s/\'/ singlequote /g;
s/--/ doubledash /g;
s/-/ singledash /g;
s/\"/ doublequote /g;
s/\,/ commainsentence /g;
s/:/ coloninsentence /g;
s/;/ semicoloninsentence /g;
s/\?/ questioninsentence /g;
s/!/ banginsentence /g;
# nonindex tracks whether a space is needed in the compressed
# data for two nonindexed words in a row
while ( /(\w['\w-]*)/g ){
if (exists $found{uc $1}){
printf SQC pack("C",$found{uc $1});
$nonindex=0;
}
else {
use Switch;
switch (uc $1){
case "COMMAINSENTENCE" { print SQC pack ("C",197); }
case "COLONINSENTENCE" { print SQC pack ("C",198);}
case "SEMICOLONINSENTENCE" { print SQC pack ("C",208);}
case "QUESTIONINSENTENCE" { print SQC pack ("C",199); }
case "BANGINSENTENCE" { print SQC pack ("C",200); }
case "ENDOFSENTENCE" { print SQC pack ("C",201); }
case "DOUBLEQUOTE" { print SQC pack ("C",202); }
case "SINGLEDASH" { print SQC pack ("C",203); }
case "ENDOFPARAGRAPH" { print SQC pack ("C",204); }
case "DOUBLEDASH" { print SQC pack ("C",205); }
case "SINGLEQUOTE" { print SQC pack ("C",207); }
else {
if ($nonindex){
print SQC pack ("C",206);
$nonindex=0;
}
for ($i=0; $i<length(uc $1);$i++){
$cur=substr ((uc $1),$i,1);
print SQC pack "C",(ord($cur)+210-65);
}
$nonindex=1;
}
}
}
}
}
close SQC;
close SQ;
open (SQI, "< snowqueeni");
$i=1;
while (<SQI>){
chop;
$index{$i}=$_;
$i++;
}
close SQI;
use Term::ANSIColor;
print color(white);
open (SQC, "< snowqueenc");
$previousindex=0;
$previousnonindex=0;
# read 1 byte at a time
while (read(SQC,$ob,1) !=0){
if (ord($ob)<197){
if ($previousindex || $previousnonindex){
print " ";
}
print $index{ord($ob)};
$previousindex=1;
$previousnonindex=0;
}
else{
use Switch;
switch (ord($ob)){
case "197" { print ", "; $previousindex=0;$previousnonindex=0}
case "198" { print ": "; $previousindex=0;$previousnonindex=0}
case "199" { print "\? "; $previousindex=0;$previousnonindex=0}
case "200" { print "! "; $previousindex=0;$previousnonindex=0}
case "201" { print "\. "; $previousindex=0;$previousnonindex=0}
case "202" {
if($quoteset){
$quoteset=0;
print color(white);
}
else {
$quoteset=1;
print color(cyan);
}
$previousindex=0;$previousnonindex=0;
}
case "203" { print "-"; $previousindex=0;$previousnonindex=0}
case "204" { print "\n\n"; $previousindex=0;$previousnonindex=0}
case "205" { print "--"; $previousindex=0;$previousnonindex=0}
case "206" { print " "; $previousindex=0;$previousnonindex=0}
case "207" { print "'"; $previousindex=0;$previousnonindex=0}
case "208" { print "; "; $previousindex=0;$previousnonindex=0}
else {
if ($previousindex){
print " ";
}
printf "%c", ord($ob)-210+65;
$previousindex=0;
$previousnonindex=1;
}
}
}
}
close SQC;
|
The first part of the code creates the index file, snowqueeni. It turns out that for The Snow Queen, the best compression I could get was indexing the file if there were more than 8 instances of a word greater than 1 character. I was able to compress the file from 63,707 characters down to 33,313 characters, including the index. I can keep the index separate from the data stream, so I can put the display and decompression code on 2K of program memory, and run 32,309 bytes in sequentially from the input port. Back to the program. The found hash tracks the number of hits as the lower case key value, and the index value as the upper case key.
The next part of the program creates the compressed file, snowqueenc. There is a limited set of punctuation that I track separately. This, plus the 196 keywords in the index file, plus the upper case letters total less than 256, so I can store these in one byte. The pack command stores the integer as a single byte in the file, rather than as a sequence of numbers in the file. One problem with the compression format is that each byte is one of three identities: a keyword, a text character, or punctuation. I didn’t want to store all of the spaces in the file, since spacing is determined by the data. If the byte is a keyword byte (from the index file), then I know that I need a space under particular circumstances. If the mode switches to a series of text characters, I can put a space in. The problem is, if I go from one stream of text characters to another, that is, two words in a row that aren’t in the index file, or don’t have punctuation, then I need to embed a space token in the compressed file. The logic for when to space and when not to is a little tricky, but I’ve used comments and useful variable names, so it should be fairly clear. Another tricky command was the ord command. This returns the numeric ASCII value of the character. For instance, on this line:
print SQC pack "C",(ord($cur)+210-65); |
I’m storing one of the characters that isn’t in the index file as a byte. Since I distinguish the class of the byte by the value, I need to subtract 65, the ASCII value of A from the number, and add 210, the offset where characters start in my compression algorithm. Another tricky thing in this program is reading in characters one byte at a time:
while (read(SQC,$ob,1) !=0){
|
This line reads from the filehandle SQC one byte at a time into the variable $ob until there are no more bytes to read.
Here is a screenshot of the resulting file, when rendered by the tail end of the code:
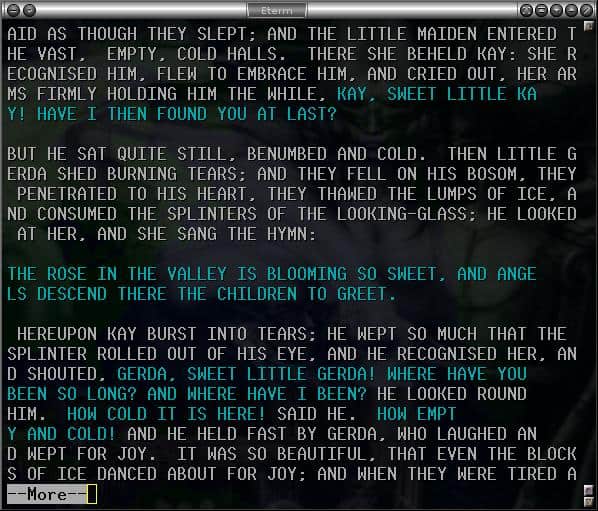
This technique does yield some pretty good compression, and would also have some cool applications with other devices with limited display capabilities.